Stitchy POC

Goal
Given the rising interest in short-form content, hyper-personalization, and meme-making, we wanted to explore some new ideas for using AI with video-making and matching. For Stitchy, we wanted to learn if we could match videos based on the words and specifically the timing of the words spoken. With this achieved, the next objective was to subjectively test the entertaining factors these stitched videos. We believe there may be latent commercial and/or marketing applications for Stitchy including physical locations (AT&T Stores, HP Store, WMIL, etc) as well as inside other applications & online experiences.
Data
Discovery
In order to create a mash-up video of words, we need to know what words were spoken within our content. ContentAI provides a large number of extractors we can use to extract words from our video assets.
ContentAI saves the results from the extractors to a data lake (S3). Most extractors provide json documents as output. The output typically includes the name, confidence and timestamp of when a thing was identified in our content.
For this POC we wanted to evaluate extractors related to finding words within our content.
Research ContentAI Extractors
Based on our transcription requirement, let's take a look at our existing (and growing) extractor library.
Azure Video Indexer
Good
Azure Video Indexer provides time segments for the video transcription. Unfortunately, we do not the start and end milliesecond segment for each spoken word.
example...
{
"id": 2,
"text": "Some days my childhood feels so very far away.",
"confidence": 0.8338,
"speakerId": 1,
"language": "en-US",
"instances": [
{
"adjustedStart": "0:00:54.74",
"adjustedEnd": "0:01:00.45",
"start": "0:00:54.74",
"end": "0:01:00.45"
}
]
},
...
GCP Video Intelligence Speech Transcription
Better
The GCP Video Intelligence Speech Transcription gives us start and end seconds for each spoken word, but it does not give us millisecond accuracy that we need for our use case. At the time of writing this blog, GCP only gives us detections rounded to the nearest tenth of a second.
example showing words with rolled up start and end second segment{
...
"alternatives": [
{
"transcript": "Some days my childhood feel, so very far away and others.",
"confidence": 0.80730265,
"words": [
{
"startTime": "54.900s",
"endTime": "55.100s",
"word": "Some",
"confidence": 0.9128386
},
{
"startTime": "55.100s",
"endTime": "55.500s",
"word": "days",
"confidence": 0.9128386
},
{
"startTime": "55.500s",
"endTime": "55.700s",
"word": "my",
"confidence": 0.9128386
},
{
"startTime": "55.700s",
"endTime": "56.300s",
"word": "childhood",
"confidence": 0.9128386
},
{
"startTime": "56.300s",
"endTime": "56.700s",
"word": "feel,",
"confidence": 0.6966612
},
{
"startTime": "56.700s",
"endTime": "57.500s",
"word": "so",
"confidence": 0.73839444
},
{
"startTime": "57.500s",
"endTime": "58s",
"word": "very",
"confidence": 0.7289259
},
{
"startTime": "58s",
"endTime": "58.400s",
"word": "far",
"confidence": 0.9128386
},
{
"startTime": "58.400s",
"endTime": "59.100s",
"word": "away",
"confidence": 0.7058842
},
...
],
...
}
AWS Transcribe
Best
AWS Transcribe gives us the start and end time segments with millisecond accuracy
example{
...
"items": [
{
"start_time": "54.74",
"end_time": "55.14",
"alternatives": [
{
"confidence": "1.0",
"content": "some"
}
],
"type": "pronunciation"
},
{
"start_time": "55.14",
"end_time": "55.49",
"alternatives": [
{
"confidence": "1.0",
"content": "days"
}
],
"type": "pronunciation"
},
{
"start_time": "55.49",
"end_time": "55.67",
"alternatives": [
{
"confidence": "1.0",
"content": "my"
}
],
"type": "pronunciation"
},
{
"start_time": "55.68",
"end_time": "56.31",
"alternatives": [
{
"confidence": "0.998",
"content": "childhood"
}
],
"type": "pronunciation"
},
{
"start_time": "56.31",
"end_time": "56.61",
"alternatives": [
{
"confidence": "0.806",
"content": "feel"
}
],
"type": "pronunciation"
},
{
"start_time": "56.62",
"end_time": "57.4",
"alternatives": [
{
"confidence": "1.0",
"content": "so"
}
],
"type": "pronunciation"
},
{
"start_time": "57.41",
"end_time": "57.89",
"alternatives": [
{
"confidence": "1.0",
"content": "very"
}
],
"type": "pronunciation"
},
{
"start_time": "57.89",
"end_time": "58.34",
"alternatives": [
{
"confidence": "1.0",
"content": "far"
}
],
"type": "pronunciation"
},
{
"start_time": "58.34",
"end_time": "58.85",
"alternatives": [
{
"confidence": "1.0",
"content": "away"
}
],
"type": "pronunciation"
},
{
"start_time": "60.44",
"end_time": "60.65",
"alternatives": [
{
"confidence": "1.0",
"content": "and"
}
],
"type": "pronunciation"
},
...
],
...
}
New ContentAI Workflow
Workflow
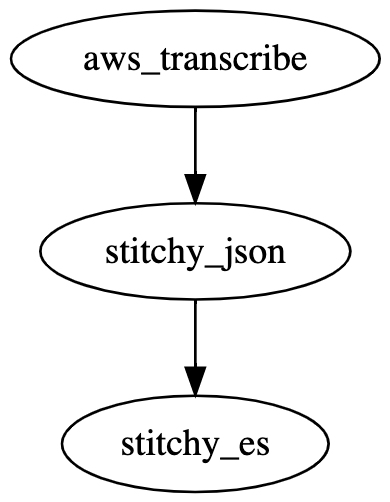
We created two new extractors stitchy_json and stitchy_es which uses the results from metadata and aws_transcribe, using the platforms extractor-chaining functionality to ..
aws_transcribeget the words we want to be able to search on.stitchy_jsonproduce a json format we will feed to Elasticsearch in the next step.stithcy_esinsert data into an Elasticsearch index.
Batch processing script
We used the new batch processing feature provided by the ContentAI CLI to run a large number of video assets concurrently. You can learn how to get started with the ContentAI CLI by checking out the docs.
{
"workflow": "digraph { aws_transcribe -> stitchy_json; metadata -> stitchy_json; stitchy_json -> stitchy_es }",
"metadata": {
"name": "Stitchy",
"description": "elasticsearch and s3 writes"
},
"content": {
"https://content-prod.s3.amazonaws.com/videos/wirewax/FreshPrinceS474.mp4": {
"metadata": {
"franchise": "Fresh Prince",
"season": 4,
"episode": 74
}
},
"https://content-prod.s3.amazonaws.com/videos/wirewax/FreshPrinceS475.mp4": {
"metadata": {
"franchise": "Fresh Prince",
"season": 4,
"episode": 75
}
},
...
...
}
}
See the full batch processing file here
Notice we include metadata as a simple way to pass additional information about the video.
Elasticsearch
We decided to use Elasticsearch for storing and searching our data. Elasticsearch meets our needs for fast retrieval for your query request.
Index example
...,
{
"id": "314313b-4865-db0a-87a6-c5f6b5851d76",
"_id": "content-prod/videos/ipv/seinfeld_601_air_cid-3H89H-201807102007369418-4ee06cad-df2a-496a-929b-e62d13e0fc4b.mp4/60240",
"_index": "stitchy",
"_score": 0.6624425,
"_source": {
"id": "content-prod/videos/ipv/seinfeld_601_air_cid-3H89H-201807102007369418-4ee06cad-df2a-496a-929b-e62d13e0fc4b.mp4/60240",
"bucket": "content-prod",
"key": "videos/ipv/seinfeld_601_air_cid-3H89H-201807102007369418-4ee06cad-df2a-496a-929b-e62d13e0fc4b.mp4",
"startTimeSeconds": 60.24,
"endTimeSeconds": 60.34,
"word": "the",
"duration": 0.1,
"confidence": 0.9271
}
},
...
API
Functionality
1. take a text string as input
here we go
2. break the text string up into individual words
here
we
go
3. search ElasticSearch for each word spoken in the content we analyzed
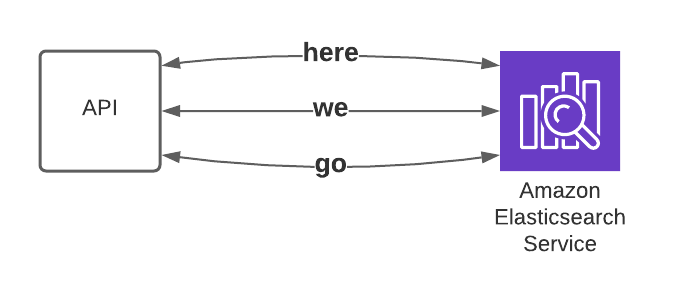
4. get contentUrl, start seconds and duration for each word of the phrase found
{
"text": "here we go",
"words": [
{
"word": "here",
"key": "videos/ipv/brooklynninenine_413_air_--3GJ3V-201805020715139434-183735.mp4",
"bucket": "content-prod",
"startTimeSeconds": 888.84,
"duration": 1
},
{
"word": "we",
"key": "videos/ipv/seinfeld_522_air_cid-3H89G-201807101758201588-7b1a93bf-3f40-492c-b3e1-a24f69c4d4ee.mp4",
"bucket": "content-prod",
"startTimeSeconds": 736.04,
"duration": 0.94
},
{
"word": "go",
"key": "videos/ipv/brooklyn99-rev1_114_air_c--36C7Y-201707180953553712-d7be371e-0a49-4ca4-84d6-7130f89c8288.mp4",
"bucket": "content-prod",
"startTimeSeconds": 316.9,
"duration": 1
}
]
}
5. create a pre-signed url for each unique contentUrl
The pre-signed URL will be used by FFMPEG to access the content
6. use FFMPEG to create a short clip of the word spoken
ffmpeg -ss 888.84 -i ${presignedUrl} -c copy -t 1.00 /tmp/0.mp4
ffmpeg -ss 736.04 -i ${presignedUrl} -c copy -t 0.94 /tmp/1.mp4
ffmpeg -ss 316.90 -i ${presignedUrl} -c copy -t 1.00 /tmp/2.mp4
7. stitch :) all clips together to create one video
We are using Fluent ffmpeg-API for node.js This library abstracts the complex command-line usage of ffmpeg into a fluent, easy to use node.js module
mergeToFile(filename, tmpdir): concatenate multiple inputs
ffmpeg('/tmp/0.mp4')
.input('/tmp/1.mp4')
.input('/tmp/2.mp4')
.on('error', function(err) {
console.log('An error occurred: ' + err.message);
})
.on('end', function() {
console.log('Merging finished !');
})
.mergeToFile('merged.mp4', '/tmp/'
8. return the url of new video
{
"url": "https://stitchy.contentai.io/videos/clips/here-we-go-kjtsy.mp4"
}
Website
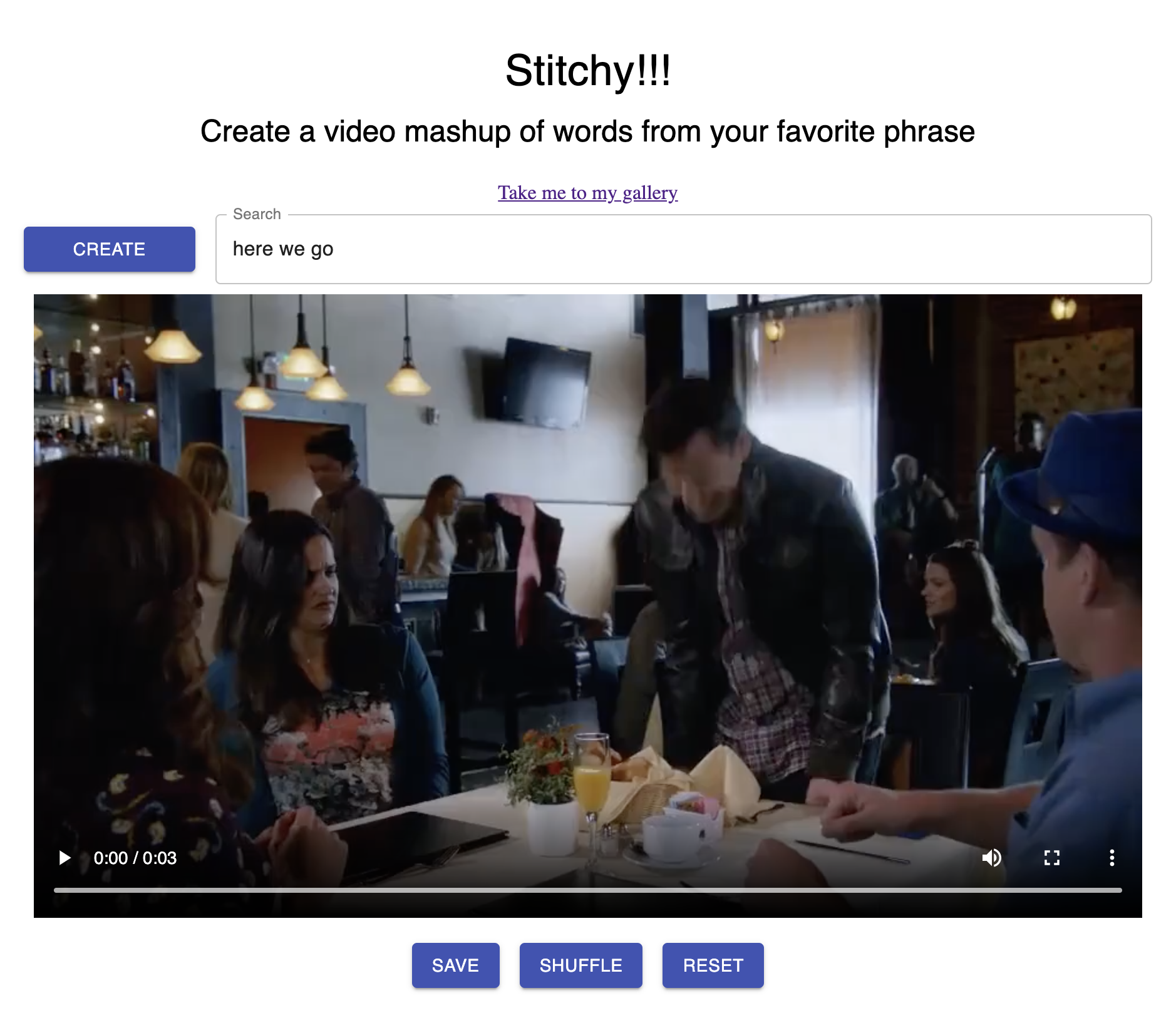
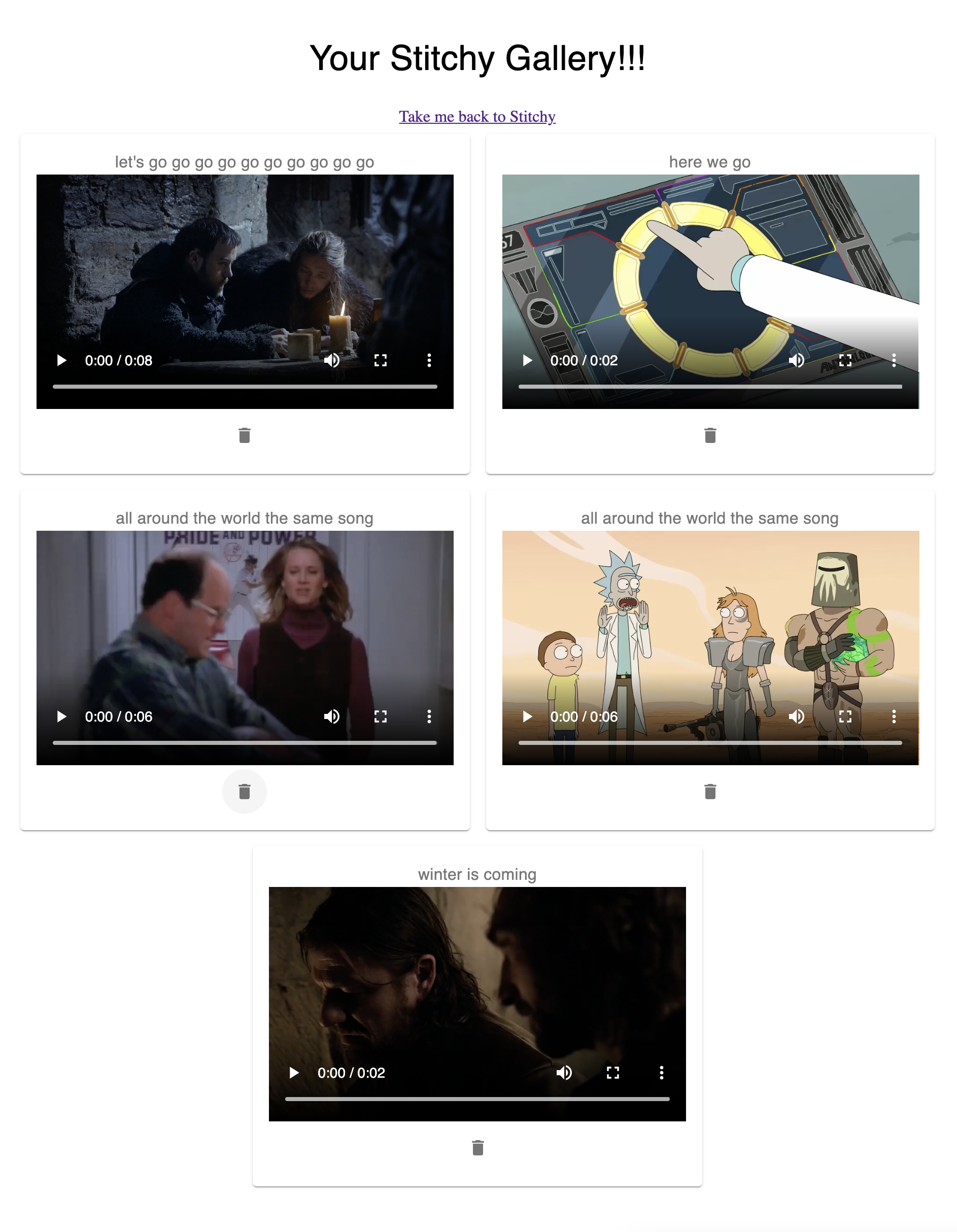
Image Gallery
You can also save some of your favorite results to your personal stitchy gallery
Cost
We ran the workflow against episodes from the following franchises
- Game of Thrones - 10 Episodes
- Rick and Morty - 19 Episodes
- Brooklyn 99 - 77 Episodes
- Seinfeld - 86 Episodes
Roughly around 82 hours of content
ContentAI
| Extractor | Cost |
|---|---|
| aws_transcribe | $497.50 |
| stitchy_json | $1.54 |
| stitchy_es | $1.54 |
| Total | $500.58 |
One of the many benefits of ContentAI is this is a one time cost. Now that the results are stored in our Data Lake they can be used by any application in the future.
To learn more about calculating the cost for your project please see visit our cost calculator page. Also, if you would like to learn more about getting the data from our Data Lake to use in your application, please check out our CLI, HTTP API and/or GraphQL API docs.
Summary
In this POC we used the power of ContentAI to extract audio transcription concurrently using our batch processing feature. Next, we took the audio transcription and pushed the metadata to Elasticsearch. We built a simple application to demonstrate what type of app we could build using the extracted metadata powered by Elasticsearch.
Acknowledgements
The main contributors of this project are Jeremy Toeman from WarnerMedia Innovation Lab and Scott Havird from WarnerMedia Cloud Platforms.