Scene Finder POC

Goal
We began this project as an exploration around up-levelling the capabilities of “assistants” (AI, chatbot, virtual, etc) with regards to the specific field of media & entertainment. As the overall platform of voice (and other) assistants increase in capabilities, we believe that they will focus on more “generic” oriented features, which gives us the opportunity to specialize in the vertical of entertainment. For this phase of work, we are exploring the concept of what an “Entertainment Assistant” might do, and how it might function.
One such function would be, for example, a voice-driven search where the user doesn’t exactly know what they are looking for: “Show me the first time we see Jon Snow in Game of Thrones” or “Show me dance scenes from classic movies” or “Show me that scene from Friends where they say ‘we were on a break!”.
In other words: respond to a voice-based command, filter out the relevant keywords, and deliver to the user all the matching scene-based results.
ContentAI
ContentAI provides the ability to use the latest and greatest computer vision and NLP models provided by cloud providers AWS, Azure and GCP as well as custom models contributed to the platform from our partners, AT&T Research Labs and Xandr.
Data
Discovery
To be able to search for things within our content...we need to know what is in our content down to each second of content. ContentAI provides a large number of extractors we can easily use to pull timecode insights from our video assets.
ContentAI saves the results from the extractors to a data lake (S3). Most extractors provide json documents as output. The output typically includes the name, confidence and timestamp of when a tag was identified in our content.
We used Snowflake to query the ContentAI data lake to discover what tags each extractor identified in our content. We searched through the list of tags and found some we were initially interested in. Next step is to start a ContentAI job to produce results on the content we care about.
Loader
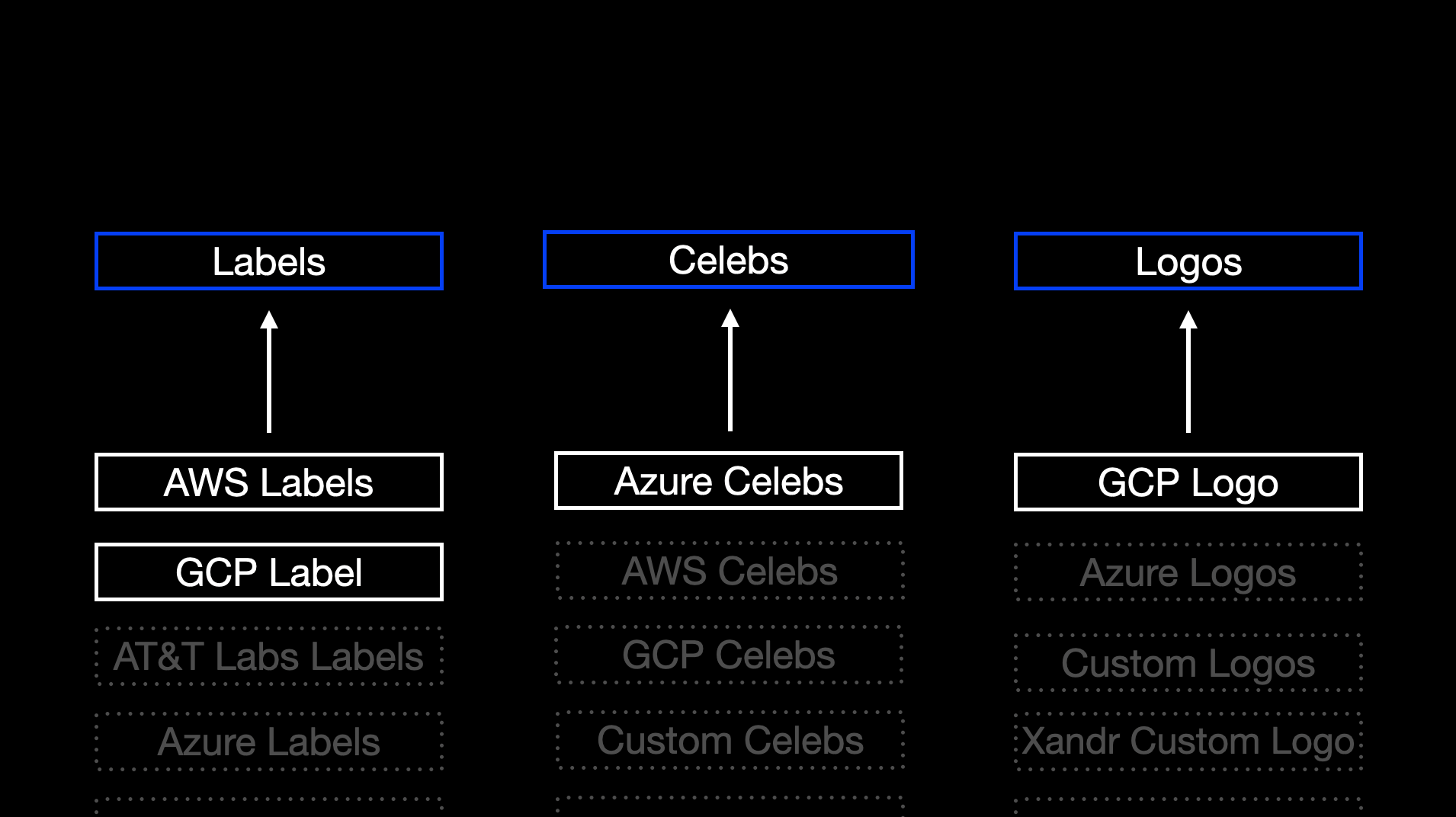
For the Proof of Concept (POC) we decided to use a small set of extractors to produce some data that would be interesting to search against. We decided on Labels, Celebrities and Logos.
- AWS Rekogntiion Video Labels
- GCP Video Intelligence Label
- Azure Video Indexer Celebs
- GCP Video Intelligence Logo Recognition
We ran ContentAI jobs to produce data. You can learn how to get started with the ContentAI CLI by checking out the docs.
Here is an example of running a ContentAI job for the first episode from the first season of Game of Thrones executing the extractors listed above.
contentai run s3://content-prod/videos/HBO/ai_got_01_winter_is_coming_263255_PRO35_10-out.mp4 -w 'digraph {
aws_rekognition_video_labels;
azure_videoindexer;
gcp_upload -> gcp_videointelligence_label;
gcp_upload -> gcp_videointelligence_logo_recognition;
}'
To see the results from the first episode without having to run the entire video through ContentAI again, please see results from the ContentAI jobs we executed to create this POC.
For example, you can download the data produced by running all extractors for episode one from Game of Thrones by running this command using the ContentAI CLI. Give it a try.
contentai data 1aE9aJHk6cz2ENeEgkwYTKjvAXS
We repeated the above steps for the remaining episodes from the first season of Game of Thrones.
We decided to use Elasticsearch for storing and searching our data. We have some experience with Elasticsearch and it meets our needs for fast, full-text search.

With the raw results from running the ContentAI Jobs, we decided to group the results from the extractors into buckets...Labels, Celebs and Logos. We combined the results from AWS Labels and GCP Label into a distinct list of label names and added them to the label bucket.
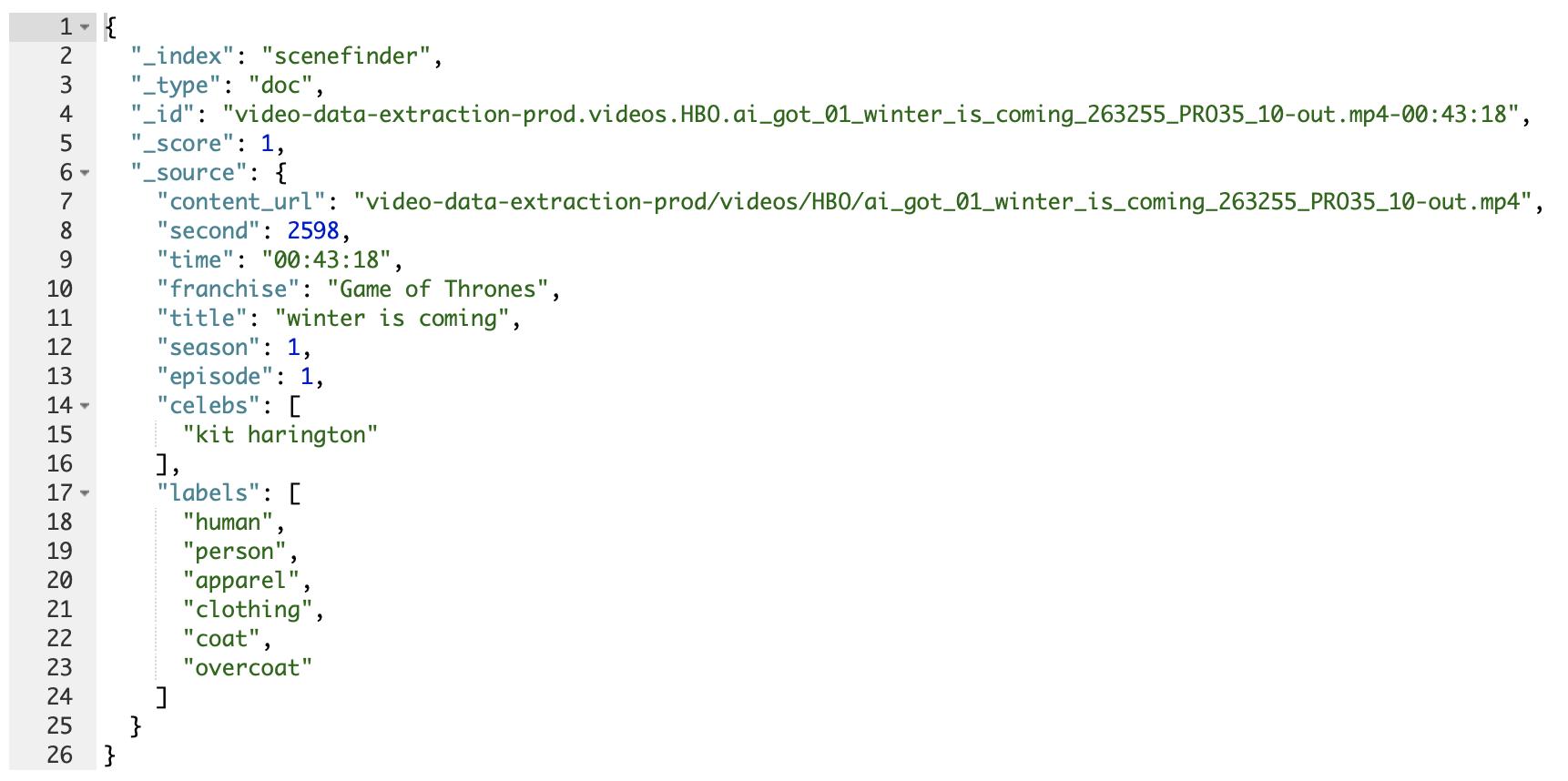
Extractors are independent from one another, each can provide different ways to produce the results. Some extractors provide us with what tags are discovered at a particular millisecond in time, while other extractors will provide us with a tag and the time segments where it was identified within content. For simplicity when searching, we are storing an aggregate of the results to the second. Also, we only pulled in tags where the confidence was greater than 90%.
API
The API will take in a text string “Show me scenes with kit harington and a blizzard” and return all occurrences where “kit harington AND blizzard” showed up in our Elasticsearch index.
From the original search text, we want to pull out known tags and operators so we can create a query string for Elasticsearch.
We can then search the text string for tags that we've previously found when processing them through ContentAI. Once we have the known tags and the operators from the original text, we can construct a query for Elasticsearch.
Output
{
"text": "Show me scenes with kit harington and a blizzard",
"query": "kit harington AND blizzard",
"results": [
{
"franchise": "Game Of Thrones",
"season": 1,
"episode": 2,
"confidence": 74,
"filename": "*.mp4",
"milliseconds": 708000,
"celebs": ["emilia clarke"],
"labels": ["person", "castle"]
},
{
"franchise": "Game Of Thrones",
"season": 8,
"episode": 4,
"confidence": 59,
"filename": "*.mp4",
"milliseconds": 1033000,
"celebs": ["emilia clarke"],
"labels": ["table", "castle", "tea"],
"logos": ["starbucks"]
}
...
]
}
Website
Mock

Tasks
We came up with a list of tasks to build the website based on the initial screen mock ups.
- Display raw elastic search results
- Added keyframe artwork
- Speech recognition
- Play video
Once the initial tasks were completed, we started bouncing ideas around what else we could add to the website to make it more compelling for a demo. Since the API was doing some magic to send a query to the Elasticsearch, we decided to display what was sent to elastic search. Next we wanted to give users the ability to click on the other tags associated with this document.
- Display what was sent to Elasticsearch (added query attribute to the API output)
- Add clickable tags (added labels, celebs, logos to the results collection on the API output)
Final
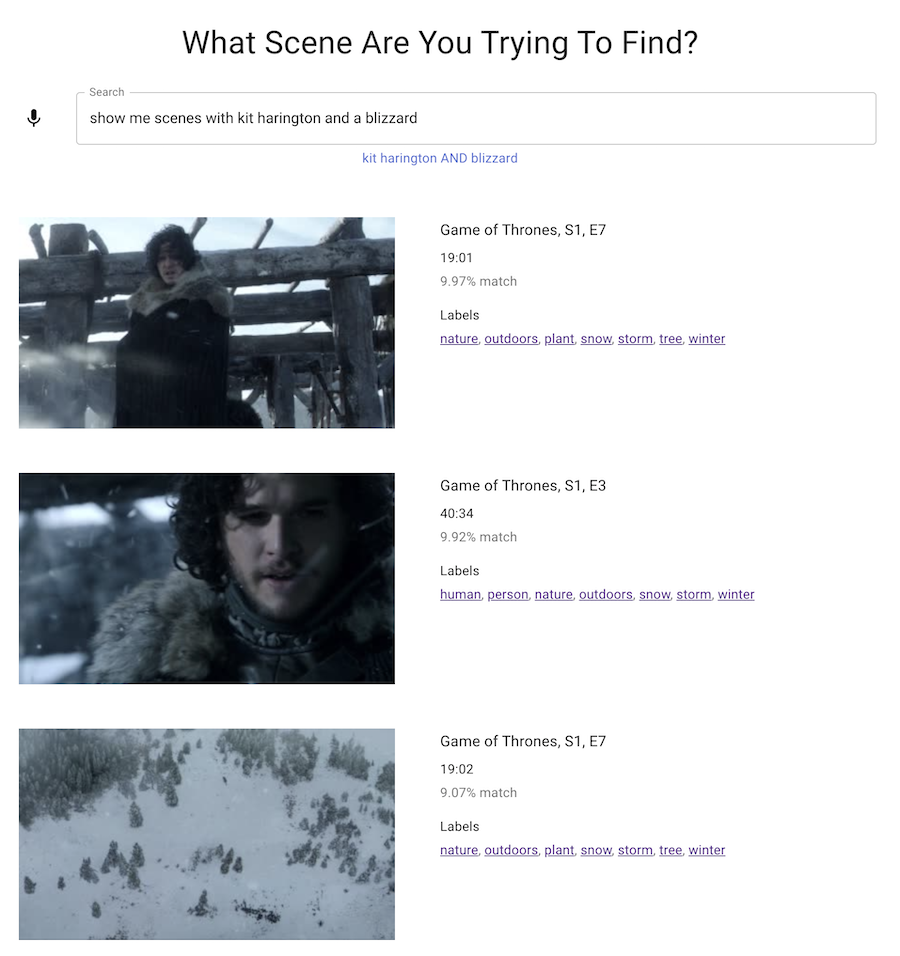
Future Enhancements
- Instead of performing a string lookup to identify known tags from the search text, we could’ve used a cloud managed service like Amazon Comprehend Custom Classification to perform that lookup task for us. Amazon Comprehend is a natural language processing service that uses machine learning to find insight and relationships in text. No machine learning experience is required.
- I would really like to dig deeper into Elasticsearch's functionality. My hunch is that there are more advanced capabilites that we may not be taking advantage of.
- Adding more extractors would further enrich the searchability of the app.
Contributors
- Jeremy Toeman - WarnerMedia Innovation Lab
- Scott Havird - WarnerMedia Cloud Platforms
Related Posts
- Auto Sizzle Reel — AI-powered sizzle reel extraction for HBO Max
- Getting Started Exploring Extracted Data — Working with ContentAI extracted video data